申明: 大部分内容来源于网络,我不生产知识,我只是字符串搬运工。
如何在高并发的情况下,提高多核CPU的性能,一直是在并发编程领域中非常重要的问题。 特别是随着云厂商按计算收费的当下,如何有效地利用计算资源变得更重要。
致富的途径只有两种:一种是拼命赚钱,另外一种就是有钱后节约花钱。
什么是锁
在计算机硬件层其实是没有锁这个概念的,计算机领域中的锁来源于现实生活中的锁,它的作用是保护某种资源同一时间不能被多人访问。现代计算机已经发展成了多核CPU处理器,我们需要通过锁机制来协调多个内核对资源的访问操作。
和现实中一样,在给资源上锁的时候,我们可能需要几个步骤:
- 拿出钥匙
- 锁上资源
- 解锁
计算机中对应的CPU操作就是执行几条指令(CPU每条执行指令都是原子级别的操作,要么成功,要么失败,这是二进制世界的规则)。
这里罗列几条与后面要讲到的锁相关的硬件同步汇编指令
- test_and_set
- swap
- get_and_add
test_and_set 由3条CPU原语组成
|
|
BTS 指令含义是在执行 BT 命令的同时, 把操作数的指定位置为 1
|
|
swap也是由三条CPU原语组成: BSWAP指令含义是:把32/64位寄存器的值按照低和高的字节交换(下面代码实现其实就是0=false,1=true交换)
|
|
上面简要地说明了通过CPU硬件同步原语,对某个内存地址标志位的修改,起到加锁的作用。
那么锁机制和性能有什么关系呢?这得从内存(Memory),CPU缓存说起。
多核CPU多级缓存架构
早期的CPU架构基本上都采用SMP(Symmetric Multi-Processor),这种对称多处理器结构,多个CPU内核共享内存资源,除了内存速度访问慢以外, 还可能导致访问冲突。
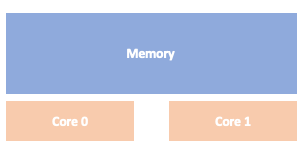
所有CPU通过北桥访问内存,访问带宽也是一个问题。
现代CPU为了提高数据的访问速度,采用了NUMA(Non-Uniform Memory Access)多级缓存的架构,每个内核都有自己的缓存,如下图:
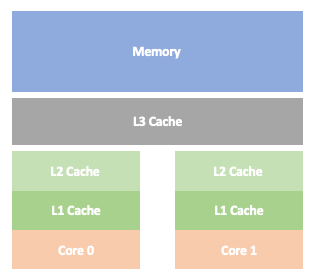
由于内存读取速度的较慢(科技发展遇到了阻碍?),但是CPU计算速度提升较快,所以CPU厂商才在内存和CPU之间加了多级缓存来缓解速度的不对等,充分利用CPU。来自Red Hat工程师这篇What Every Programmer Should Know About Memory 论文进行了详细的介绍,为何要设计多级CPU缓存。
其他的处理器架构可以阅读Overview of Recent Supercomputers,后面讨论相关锁算法的时候会基于某个处理器架构来说。
但这里我们只需要有一个直观的理解,如下图:

内核首先从L1缓存中读取数据,如果没有就到L2缓存中读取,如果没有就到 L3缓存中去读取,最坏的情况就是L3缓存也没有,那就只能到内存中去读取。
但这种方案也不是没有限制,因为越是靠近内核的缓存越贵,不能肆意地设计得很大。
CPU缓存读写
当多个内核在对同一块数据做加锁操作时:
- CPU1 从内存中读取一个字节,以及它和它相邻的字节被读入 CPU1 的高速缓存(因为CPU的高速缓存最小单位是行Cache Line)
- CPU2 和CPU1同样的操作
- CPU1 完成数据修改,通过内存总线控制,写回内存
- CPU2 高速缓存数据失效,重新读取
这个过程中,如果CPU1修改完数据,还没有写回内存时,CPU1与CPU2的高速缓存数据是不一致的,这时CPU通过内存总线 缓存协议MESI来保证一致性。
可以看出,数据加锁这个操作非常复杂。特别是在多个内核之间共享数据。
更详细的内存架构介绍,建议阅读:圖解RAM結構與原理,系統記憶體的Channel、Chip與Bank
自旋锁
上面介绍了CPU多级缓存架构,有助于理解后面锁相关的性能问题。同时上面还提到了一种硬件同步锁实现test_and_set,从实现中你可能发现代码中使用了:
|
|
这就是自旋锁机制,自旋锁的原理是,如果锁被别的执行单元保持,那么调用者就一直循环在那里查看锁保持者是否释放了锁,即忙则等待。
这里有个细节就是等待锁的调用者并不是休眠,而是一直在工作占用CPU。
结合上面提到的多核多级CPU缓存,如果当多个内核执行单元都在调用获取锁时,没有获取到锁的内核将一直繁忙,处于中断状态。
所以这种自旋锁的缺点就是:
- 容易导致死锁
- 过度消耗CPU资源
- 竞争不具备公平性
第2点,业界经过测试发现test_and_set锁随着线程和内核的增长,会导致Exponential backoff,
“Exponential backoff is an algorithm that uses feedback to multiplicatively decrease the rate of some process, in order to gradually find an acceptable rate.”
指数补偿重试等待算法在CPU内核方面并不是适用(适用于网络请求场景中)。
对于第3点,很容易想到,如果执行单元释放了锁,后面哪个执行单元会获取到锁呢?这里没有机制保证每个执行单元都能获取到锁。
CLH锁
基于上面说的缺点,1993年由Travis Craig,Anders Landin 和 Eric Hagersten,提出了CLH锁,它也是一个自旋锁。
CLH锁解决了饥饿问题,通过FIFO来保证公平性。
CLH锁也是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
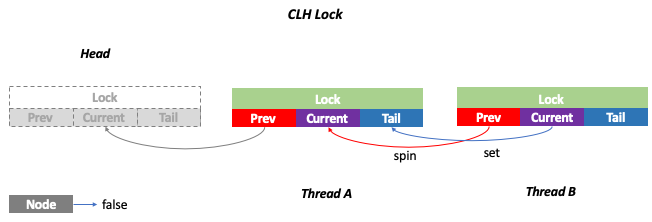
CLH锁的实现如下:
- 两个ThreadLocal变量,一个表示当前节点,一个表示前趋节点
- 通过CAS原语加入队尾
- 每个线程尝试用自己去替换tail,并循环获取前趋节点上的锁,直到锁被释放。
- 线程释放锁之后,将当前节点设置为前继节点
|
|
CLH自旋锁的优点是空间复杂度低,L个线程n个锁的复杂度为O(L+n)。
JAVA中的AQS并发框架
JAVA中的AQS并发框架(java.util.concurrent.locks.AbstractQueuedSynchronizer.Node)也是基于CLH锁,但是它是一个变种,它考虑了等待队列中取消获取锁的情况,以及释放锁的线程可以向获取同一把锁的线程发送消息。
JDK中的描述:
|
|
如果你对上面讲的多核CPU多级缓存架构还有印象,那么你还是会发现CLH锁也有一个明显的缺点, 那就是:
|
|
这里的自旋可能发生在非本地缓存上,那么当内核需要循环读取一个非本地(或者说离自己很远)缓存中的数据时,在多级缓存架构中那就是个灾难,因为每一次读写都要通过控制器和总线(这和上面提到的SMP和NUMA处理器架构息息相关),带来极大的开销。
于是就有了……
MCS锁
1991年这篇Algorithms for scalable synchronization on shared-memory multiprocessors论文提出了MCS(John Mellor-Crummey and Michael Scott)锁,针对CLH锁进行了优化,其主要区别是自旋发生在本地节点上。
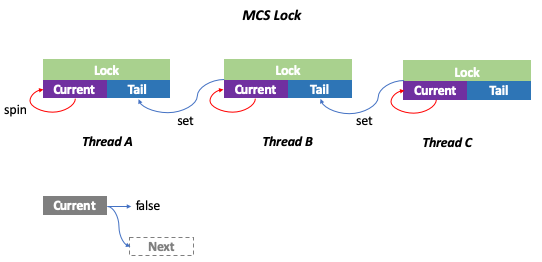
实现如下:
- 队列初始化时没有结点,tail=null
- 线程A想要获取锁,于是将自己置于队尾,由于它是第一个结点,它的locked域为false
- 线程B和C相继加入队列,a->next=b,b->next=c。且B和C现在没有获取锁,处于等待状态,所以它们的locked域为true, 尾指针指向线程C对应的结点
- 线程A释放锁后,顺着它的next指针找到了线程B,并把B的locked域设置为false。这一动作会触发线程B获取锁
|
|
总结
自旋锁通过忙则等待的机制占用CPU资源,但这样的好处也是有的,防止线程上下文切换(参考CPU缓存读写一节),这和互斥锁是有很大区别。
同时由于占用CPU资源的问题,在实际使用过程中,尽量让被保护的临界区小,保证可以快速地释放锁。